Download PDF
Download page Custom Provisions.
Custom Provisions
Provisions are available from built-in libraries. Syncing the Provision Library to the publisher (AI provider) makes these provisions available for data extraction mapping. However, if your specific contract language does not conform to any of these preconfigured provision types, you can name, build, populate, and train the AI on your own custom provision type.
To add a custom provision
Successive generations of Conga Discovery AI have progressively reduced the resources required to train an AI to recognize and extract values from documents. Generative AI reduces the training requirement to zero. The administrator configures the generative AI search with two examples. Once the examples are added and the provision is saved and mapped to a worksheet, no additional user training input is expected: the provision extracts from imported documents automatically.
Warning
There is an issue with custom provisions. When the user reviews clauses from an extracted document, the on-screen highlight may not match the information gathered correctly by the AI-generated provision. This issue affects only clauses, not fields. It is scheduled for repair.
Before adding custom clause provisions, alert users to this issue.
- From the left navigation bar of the Conga Start window, select the menu icon (
 ) and then pick Admin Apps.
) and then pick Admin Apps. - Click the AI icon (
 ) to open the Discovery AI admin/management view.
) to open the Discovery AI admin/management view. - Click the Admin Dashboard button to raise the Discovery AI Admin Home page.
- From the Admin Dashboard (Admin Home), click the Provision Library tab in the left navigation bar to open the Provision Library.
- Review the existing provisions carefully to ensure that the provision you want isn't already provided. Entering key terms in the Search & Filter field at right is a good way to shorten the list of provisions to review.
- If the provision you want isn't available, click the NEW PROVISION button to raise the New Provision window. Enter the new provision's name and select the annotation data type. Further choices depend on this selection. From the available choices (Date, Organization, Currency, Duration, Number, Percent, Picklist, Short Text, Text, Table) Picklist and Table offer additional settings.
- For all except Picklist and Table, select the language, minimum accuracy threshold, acceptable confidence score, maximum extractions to display for review, and enter a description of the provision. Alphanumeric characters are allowed. Duplicate provision names are also allowed.

Tip
Enter clear, natural, space-separated names in the Name field, which prompts the generative AI model in the background.
Do:
Effective DateDon't:
Effective_Date1E.Date.CustomThe Description field conveys the provision's meaning to the generative AI model. In this field, provide clear phrases that describe what is to be extracted from the document. For example, the description offered to extract the effective date only if it is mentioned might be: “The date on which agreement becomes effective”. If you also consider the contract date as the effective date, the description might be: “The date on which the agreement becomes effective or is entered into.”
- For Picklist data types, select the data type (Date, Organization, Currency, Duration, Number, Percent, Short Text, or Text) and enter comma-separated values in the Add values for picklist field.
- For Table data types, select a preconfigured table from the Choose Table field.
- For all data types except Table, you must select a language (default: English) and you may adjust the Minimum Accuracy Threshold (expressed as a percentage), the Acceptable Confidence Score (a decimal between 0 and 1), and the Maximum Extractions to Display for Review. For more on these, see Minimum Accuracy Threshold: Theory, below.
- Click NEXT.
- For all except Picklist and Table, select the language, minimum accuracy threshold, acceptable confidence score, maximum extractions to display for review, and enter a description of the provision. Alphanumeric characters are allowed. Duplicate provision names are also allowed.
- The Provision Example window prompts you to add two new examples. Click ADD EXAMPLE.
- If any examples are available, they are displayed in the resulting New Provision window. Otherwise, you must click NEW to add an example.
- In the "Add example" pop-up, enter (or paste in) the paragraph text you will extract and the data you want to extract.

Tip
For fields, enter the sentence, paragraph, or clause where the field is usually found in the Paragraph Text field.
For example:
This agreement is entered into on 1/1/2024 by and between ABC Inc., a Delaware company, and XYZ LLC, headquartered in San Jose.In this example, enter
1/1/2024in the Data to Extract field.For clauses, enter a sentence, paragraph, or clause in the Paragraph Text field that is similar to or exactly the clause to be extracted.
For example:
No Party shall be liable or responsible to the other Party, nor be deemed to have defaulted under or breached this Agreement when delay is caused by or results from acts of God.In this example, enter the same clause information in the Data to Extract field, as the extraction involves the entire clause or paragraph.
- Click Add another example and repeat the preceding substep with another example. You must provide at least two samples for the AI to work.
- Click ADD.
- In the "Add example" pop-up, enter (or paste in) the paragraph text you will extract and the data you want to extract.
- Your entry is now available in the Examples table.
- When you have entered all your examples, click DONE. You will receive a success message and see a summary of the new provision.
Your new custom provision is available in the Provision Library and is active by default.
There is no manual training flow. If the AI does not produce the desired accuracy, add more examples to the provision as described above.
Managing Annotations
Annotations are feedback left by reviewers as they review the document extractions. They consist of:
- Thumbs-up/thumbs-down indications
- Text selections from documents associated with a provision
- Edits to text selections and extractions
The AI uses all these types of information to train itself. For a given custom provision, you can include the annotations reviewers have made or delete them, removing them from AI training.
A thumbs-up or thumbs-down sends the extraction to the AI model for training, and user feedback is only valid if either a thumbs-up or thumbs-down is selected. If neither is selected, changes (add, update, or delete) made to an extraction are not sent to the AI for training. If the extraction is annotated (an add or update) and you select the checkbox to the left, your annotation is saved to the agreement record even if you do not select thumbs-up or thumbs-down feedback.
To review annotations
- From the left navigation bar of the Conga Start window, select the menu icon () and then pick Admin Apps.
- Click the AI icon () to open Discovery AI's administrative view.
- Click the Admin Dashboard button to raise the Discovery AI Admin Home page.
- From the Admin Dashboard (Admin Home), click the Provision Library tab in the left navigation bar to open the Provision Library.
- Click the name of an existing custom provision.
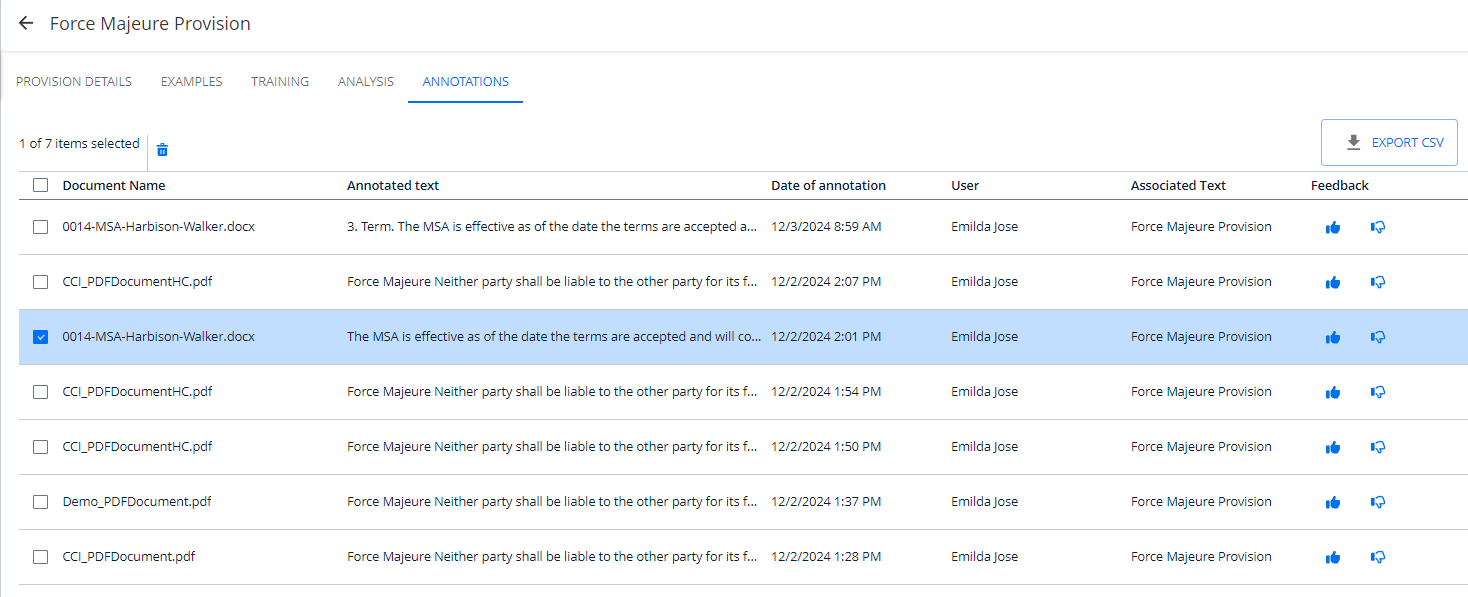
- Click the ANNOTATIONS tab.
- The default view shows columns for document name, the content of the annotation, the date of the review, and feedback (a thumbs-up or thumbs-down indication).
- Under the Feedback column, select the thumbs-up icon to include an annotation as suitable for training this provision, or select the thumbs-down icon to indicate a bad training example.
To delete annotations
- Follow the instructions in To review annotations to the ANNOTATIONS tab.
- Select the document annotation(s) you will remove.
- Click the Delete icon (
 ).
).
To export the Annotations table
You can review the annotations table off-platform by exporting it the tabular comma-separated value format.
- Follow the instructions in To review annotations to the ANNOTATIONS tab.
- Click the EXPORT CSV button at top right.
This generates and exports a CSV listing of all visible annotation information, irrespective of the live selections.
Training
When the total count of annotations reaches 30 for a provision, training automatically begins. You can also trigger training for a provision before 30 annotations are entered by force-training the AI on a limited set of annotations.
To manage training tasks
- Open the Provision Library and select a provision as described in To review annotations.
- Click the TRAINING tab.
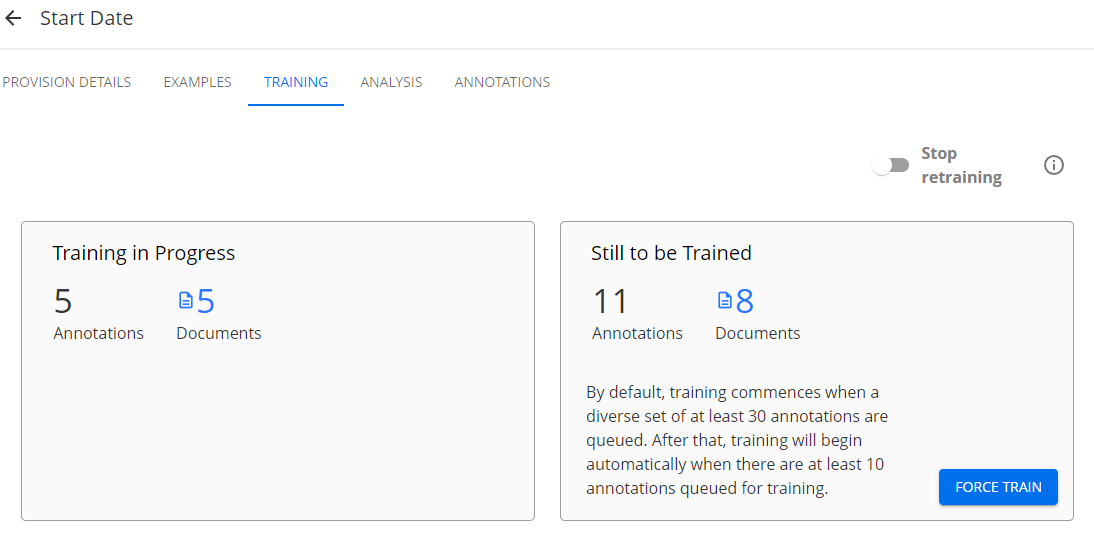
The Training in Progress pane at left describes the documents containing the subject provision that have already been annotated and the total number of annotations in the reviews. The Still to Be Trained pane accounts for remaining annotations and documents. - Flipping the Stop retraining toggle on forces to AI to use the training it has already received to find future provisions. This reduces review latency but may cost accuracy if turned on before the AI is fully trained.
- AI training normally activates after 30 annotations (thumbs-up/-down marks, text selections, or selection edits) have been entered. Clicking the FORCE TRAIN button pushes the AI out of training mode immediately. This may save time but may also cost accuracy.

Note
Force-training with fewer than five annotations is not recommended.
Table Extraction
You can use AI to extract tables from documents. This is especially useful when contracts present such tabular data as bills of materials or delivery schedules. Because table extraction requires generative AI, these extractions do not require training. Users can extract tables as soon as the table extraction is configured and mapped to a worksheet.
Each table must have a vertical columnar structure, with each line reflecting the values named in the heading. Discovery AI extracts these values in much the same way it handles fields and clauses, presenting this data in a column-defined line-item format.
To configure a custom provision with table extraction
- Follow the procedures for To add a custom provision (above) to step 6c.
- Select Table from the Annotation Data Type dropdown menu. Some screen options (Based on Provision, Minimum Accuracy Threshold, etc.) disappear.
- Select a table by name from the Choose a Table dropdown menu. These tables are defined in CLM. You can set up new tables in CLM by following the instructions for adding contract line items.
- Click NEXT.
- Click ADD COLUMNS to raise the Add Alternate Keywords for Columns pop-up.
- Select a column name from the Choose Column drop-down that you want the AI to extract. This populates the adjacent Add Values for Keywords cell.
- Click the NEW COLUMN button to add columns to extract. Add columns in the order you want this information presented. The order you see here is the presentation order of the extraction, irrespective of the order the columns fall in the scanned table. You are not required to select every column.
Note
The order of the columns here controls the order in which they are presented to the reviewer. To change the order, you must delete and add columns until you achieve the desired order. It is therefore a good idea to have the presentation order in mind before you begin.
- You must click the checkbox adjacent to one of the columns to set it as the primary column. This identifies the essential property of the line without which there would be no line. For example, on a line containing the column heads "Deliverable", "Quantity", and "Unit Price", the Deliverable column is the reasonable primary choice, as there is no quantity or price without a deliverable product. Primary selection does not affect the presented order of the columns, but it is the "handle" by which reviewers will access and sign off on the extracted data.
- For each column, enter keywords as comma-separated text in the Add Values for Keywords field approximating likely column headings to enhance the AI's likelihood of accurate extraction. For example, if you know a column normally titled "Description" is occasionally titled "Desc.", you can enter that alias here.
- You can check the Strict Name Match box to enforce verbatim column-heading matches. Leaving this unchecked permits AI matching.
- If the table type contains hierarchic data, indicated by regularly indented rows in existing columns, you can set a hierarchic value for the column entry. For example, if a table has a column named "Prices" with sub-entries for "$1–$5,000", "$5,001–$10,000" etc., you can select the Prices column from the Choose Column field, populate the Add Values for Keywords field with entries of "$1–$5000", "$5001–$10000", and so forth, and assign Hierarchy level 1 in the Type field.
Tip
Do not enter values with commas except to divide entries. Entries in the Add Values for Keywords field are comma-delimited, so your entries will be broken into fragments at each comma.
- When you have selected and described all columns desired for extraction, click ADD to review your columns.
- You can slide the Match exact column count toggle to ignore tables with an unexpected number of columns.
- Click DONE to save the new custom provision and return to the Provision Library.
Minimum Accuracy Threshold: Theory
It is important to have a working understanding of the accuracy and confidence scores, as these are the final criteria by which you will measure the AI's performance in recognizing your custom provision. As the F1 score is a factor of accuracy, precision, and recall, it is worthwhile to have a basic understanding of these foundational concepts. Once a provision is trained enough to produce a meaningful statistical sample, you can fine-tune the results based on the AI model's confidence score.
Accuracy
Accuracy describes the ratio of true positive and negative identifications for all samples. The ratio of true positives detected to all actual positives is classified as recall. The ratio of true predicted positive results to all (true and false) predicted positives results is called precision. These are combined to form an F1 score.
Precision
Precision is a measure of the AI's predictive correctness. For example, if the AI is asked to find apples in a mixed basket of fruit, a perfect precision score of 1.00 means every fruit it found was an apple. This does not indicate whether it found all the apples. Expressed mathematically:
precision = true positives / (true positives + false positives)
Recall
Recall is a measure of completeness. For example, if the AI is to find apples in a mixed basket of fruit, a perfect recall score of 1.00 means it found all the apples in the basket. This does not indicate it found only apples: it may have found some oranges too. Expressed mathematically:
recall = true positives / (true positives + false negatives)
Categorizing legal concepts has more variation than picking fruit, especially when the provisions are reviewed by different legal professionals; therefore, recall and precision may differ among annotators (one person’s recall of 0.90 may be someone else's 0.80). Remember this when using built-in provisions and reviewing annotations.
F1 Score
The F1 score is the harmonic mean of precision and recall. It provides a more sensitive measure of accuracy than precision or recall alone. Expressed mathematically:
F1 = 2 * [(precision * recall) / (precision + recall)].
The F1 score gives equal weight to both precision and recall for measuring a system's overall accuracy. Unlike other accuracy metrics, the total number of observations is not important. The F1 score value can provide high-level information about an AI model’s output quality, enabling sensitive tuning to optimize both precision and recall.
When setting up custom provisions, you are asked to enter a desired minimum accuracy threshold. This is anF1 score, and Conga recommends you set this value to 65, which we have found optimally weights AI precision vs. trainer time.
Prediction Threshold
Also called a confidence threshold, this is presented in our app as the Acceptable Confidence Score. This value describes a confidence level above which information is accepted and below which it is rejected. If the threshold is set to 0, all responses exceed the threshold and are accepted. If the threshold is set to 1, then no response exceeds the threshold and all are rejected.
In general:
- Increasing the prediction (confidence) threshold lowers recall and improves precision (i.e., biases towards true positives, but throws some good results away).
- Decreasing the prediction threshold improves recall and lowers precision (i.e., biases towards including more hits, but with more false positives).
If you find your results have a lot of false positives (Discovery AI identifies incorrect passages as matching results), raise the prediction threshold setting. If you find the AI is missing too many entries, i.e., not detecting passages as matching, lower this setting.