Download PDF
Download page Adding Custom Provisions.
Adding Custom Provisions
Provisions are available from built-in libraries. Syncing the Provision Library to the publisher (AI provider) makes these provisions available for data extraction mapping. However, if your specific contract language does not conform to any of these preconfigured provision types, you can name, build, populate, and train the AI on your own custom provision type.
To add a custom provision
- Click the Provision Library tab in the left navigation bar to open the Provision Library.
- Review the existing provisions carefully to ensure that the provision you want isn't already provided. Entering key terms in the Search field is a good way to limit the list of provisions.
- If the provision you want isn't available, click the NEW button to raise the Create New Provision window. The DETAILS & SETTINGS tab is available and the TRAINING and ANALYSIS tabs are disabled.
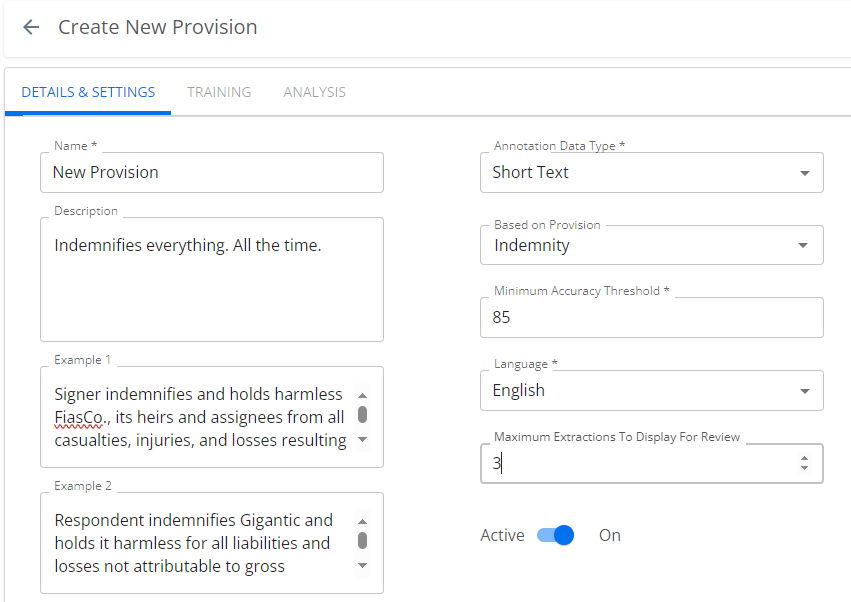
- In the DETAILS & SETTINGS tab:
- You must enter a name and a brief description for the new provision (Alphanumeric and select special characters are allowed. Duplicate provision names are also allowed). Select the data type (Date, Currency, Duration, Number, Percent, Picklist, Short Text, or Text).
- You must set a minimum accuracy threshold (this is expressed as a percentage) and select the language in which the anticipated contracts are written. The minimum accuracy threshold is the AI review's F1 score, expressed as a percentage. The machine learning model uses this value to determine whether to publish the custom provision and to set its status to Trained when it publishes it. Setting this too low valorizes training speed over precision. Setting it to 100 ensures that the provision can never leave training. Conga recommends setting this value to 65 as the best practice for balancing training efficiency and precision. For more detail, see Theory, below.
Set the value to 80% – 90%+ for extractions to begin only when the AI model has high confidence.
Set the value to 65% – 70% for extractions to begin even when some results may be wrong.
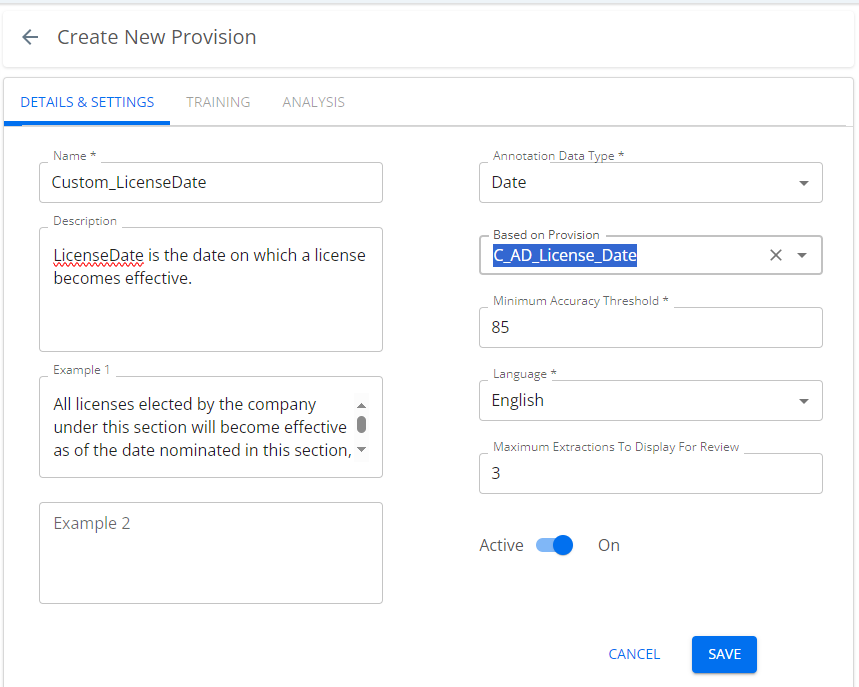
- You can speed up training by selecting a provision from the Based on Provision field and thus basing the custom provision on an existing one that is "close" to it. If your custom provision were, for example, an indemnity provision with a specific added third party, you can configure the AI to look for an indemnification clause first, then to search specifically for the peculiar third-party character of your custom provision. This makes it much easier for your users to train the AI, as it puts them "in the ballpark" without forcing them to search for the provision in the contract, and they can highlight the exact passage for training from the section already located by the "based on" provision.
In the following example, the Custom_LicenseDate provision is created using the Based on Provision field to use the existing trained provision, C_AD_License_Date.
- You may enter one or two examples of the provision text. These examples are optional, and for human readers to identify and understand the provision. They are not for the benefit of the AI.
- Set the Maximum Extractions to Display for Review field to a value that makes sense for the number and complexity of extractions you anticipate when users will review this provision.
- The Active toggle is ON by default. To revisit the Details and Settings window before training, slide it off.
- Click Save.
When you activate the provision, it becomes available for inclusion in worksheets. Once the new provision is introduced to an operating worksheet, users can see the provision and train the AI on it.
Training
Each provision must be trained on a body of documents to reach a desirable level of accuracy. This training is performed by users working through a conventional review process.
The Force Training feature shortens the training period to a configurable number, lessening training period overhead.
To force-train a provision
- From the Conga Start page, click Admin Apps.
- Click the AI icon (
 ) to open the Discovery AI admin/management view.
) to open the Discovery AI admin/management view. - Click the Admin Dashboard button to raise the Discovery AI Admin Home page.
- Click the Provision Library tab to open the Provision Library.
- Find the provision for which you will configure training and click the link text to open the provision to the DETAILS & SETTINGS tab.
- Click the TRAINING tab to raise the training window. This window reports the number of documents included and queued for training.
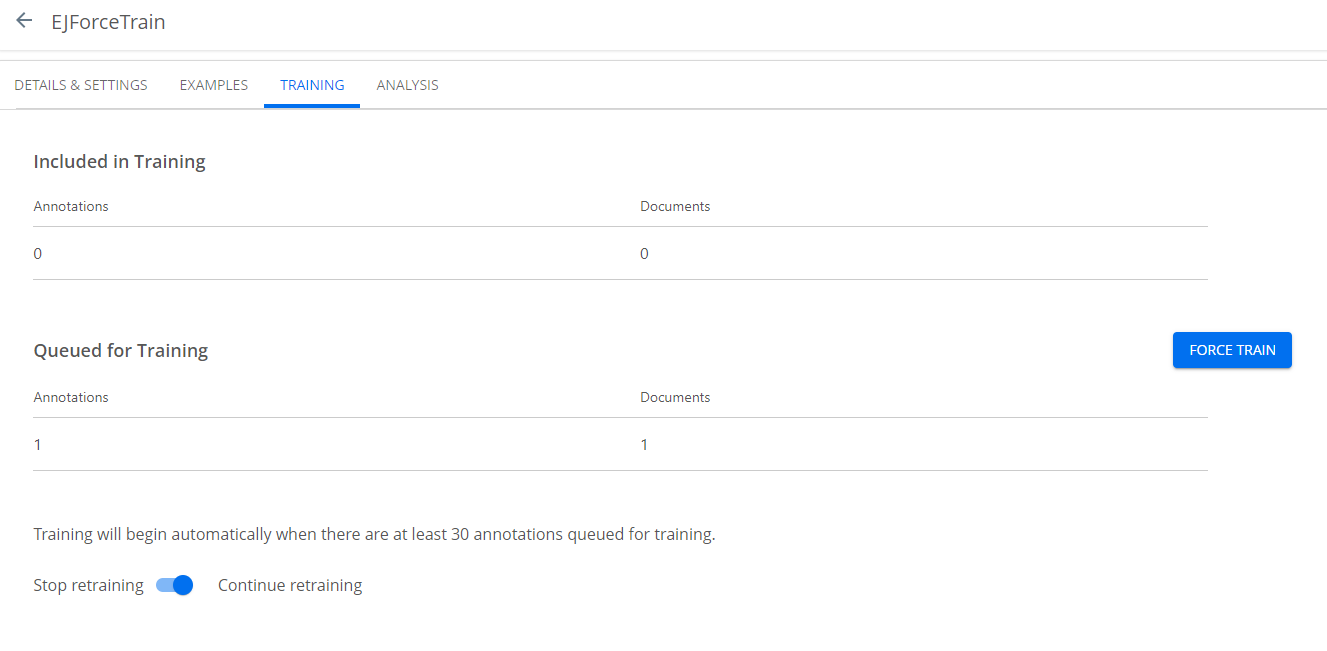
Clicking the FORCE TRAIN button sets the provision to a Trained state. By default, training commences when 30 documents are queued.

Note
It is a best practice to wait for five provisions to have been reviewed before force training. Force training prematurely will compromise accuracy.
- You can set the retraining toggle to stop or continue retraining. This feature feeds training results back to machine learning to enhance accuracy. Once you achieve a desired level of accuracy, you can switch this off.
Minimum Accuracy Threshold: Theory
It is important to have a working understanding of the accuracy and confidence scores, as these are the final criteria by which you will measure the AI's performance in recognizing your custom provision. As the F1 score is a factor of accuracy, precision, and recall, it is worthwhile to have a basic understanding of these foundational concepts. Once a provision is trained enough to produce a meaningful statistical sample, you can fine-tune the results based on the AI model's confidence score.
Accuracy
Accuracy describes the ratio of true positive and negative identifications for all samples. The ratio of true positives detected to all actual positives is classified as recall. The ratio of true predicted positive results to all (true and false) predicted positives results is called precision. These are combined to form an F1 score.
Precision
Precision is a measure of the AI's predictive correctness. For example, if the AI is asked to find apples in a mixed basket of fruit, a perfect precision score of 1.00 means every fruit it found was an apple. This does not indicate whether it found all the apples. Expressed mathematically:
precision = true positives / (true positives + false positives)
Recall
Recall is a measure of completeness. For example, if the AI is to find apples in a mixed basket of fruit, a perfect recall score of 1.00 means it found all the apples in the basket. This does not indicate it found only apples: it may have found some oranges too. Expressed mathematically:
recall = true positives / (true positives + false negatives)
Categorizing legal concepts has more variation than picking fruit, especially when the provisions are reviewed by different legal professionals; therefore, recall and precision may differ among annotators (one person’s recall of 0.90 may be someone else's 0.80). Remember this when using built-in provisions and reviewing annotations.
F1 Score
The F1 score is the harmonic mean of precision and recall. It provides a more sensitive measure of accuracy than precision or recall alone. Expressed mathematically:
F1 = 2 * [(precision * recall) / (precision + recall)].
The F1 score gives equal weight to both precision and recall for measuring a system's overall accuracy. Unlike other accuracy metrics, the total number of observations is not important. The F1 score value can provide high-level information about an AI model’s output quality, enabling sensitive tuning to optimize both precision and recall.
When setting up custom provisions, you are asked to enter a desired minimum accuracy threshold. This is anF1 score, and Conga recommends you set this value to 65, which we have found optimally weights AI precision vs. trainer time.
Prediction Threshold
Also called a confidence threshold, this is presented in our app as the Acceptable Confidence Score. This value describes a confidence level above which information is accepted and below which it is rejected. If the threshold is set to 0, all responses exceed the threshold and are accepted. If the threshold is set to 1, then no response exceeds the threshold and all are rejected.
In general:
- Increasing the prediction (confidence) threshold lowers recall and improves precision (i.e., biases towards true positives, but throws some good results away).
- Decreasing the prediction threshold improves recall and lowers precision (i.e., biases towards including more hits, but with more false positives).
If you find your results have a lot of false positives (Discovery AI identifies incorrect passages as matching results), raise the prediction threshold setting. If you find the AI is missing too many entries, i.e., not detecting passages as matching, lower this setting.