Download PDF
Download page Adding Custom Provisions.
Adding Custom Provisions
Provisions are available from built-in libraries. Syncing the Provision Library to the publisher (AI provider) makes these provisions available for data extraction mapping. However, if your specific contract language does not conform to any of these preconfigured provision types, you can name, build, populate, and train the AI on your own custom provision type.
To add a custom provision
- Click the Provision Library tab in the left navigation bar to open the Provision Library.
- Review the existing provisions carefully to ensure that the provision you want isn't already provided. Entering key terms in the Search field is a good way to limit the list of provisions.
- If the provision you want isn't available, click the NEW button to raise the DETAILS & SETTINGS tab.
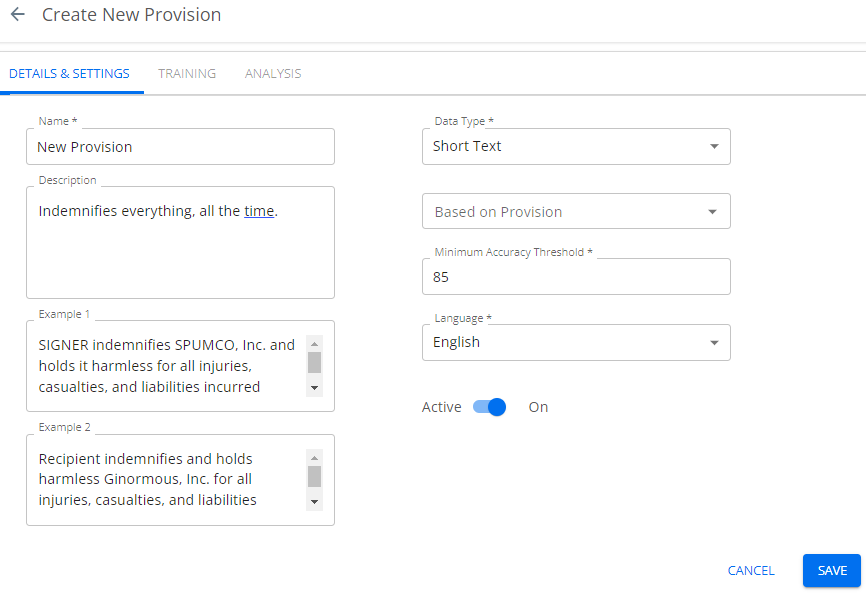
- In the DETAILS & SETTINGS tab:
- You must enter a name and a brief description for the new provision, and select the data type (Date, Currency, Duration, Number, Percent, Picklist, Short Text, or Text).
- You must set a minimum accuracy threshold (this is expressed as a percentage) and select the language in which the anticipated contracts are written. The minimum accuracy threshold is the AI review's F score, expressed as a percentage. Setting this too low valorizes training speed over precision. Setting it to 100 ensures that the provision can never leave training. Conga recommends setting this value to 65 as the best practice for balancing training efficiency and precision. For more detail, see Theory, below.
- You can speed up training by selecting a provision from the Based on Provision field and thus basing the custom provision on an existing one that is "close" to it. If your custom provision were, for example, an indemnity provision with a specific added third party, you can train the AI to look for an indemnification clause first, then to search specifically for the peculiar third-party character of your custom provision. This makes it much easier for your users to train the AI, as it puts them "in the ballpark" without forcing them to search for the provision in the contract, and they can highlight the exact passage for training from the section already located by the "based on" provision.
- You may enter one or two examples of the provision text. These examples are optional, and for human readers to identify and understand the provision. They are not for the benefit of the AI.
- The Active toggle is ON by default. If you need to revisit the Details and Settings window before training, you can slide it off.
- Click Save.
When you activate the provision, it will become available for inclusion in worksheets. Once the new provision is introduced to an operating worksheet, users can see the provision and train the AI on it.
Training Flow for Custom Provisions
After you define a custom provision, the AI must be trained to recognize the provision in ingested documents. Training the AI consists of giving the AI samples, identifying the relevant contract terms, and directing the AI to the work. Users do this in the same context and workflow as the regular document review for built-in provisions. Once you have defined the custom provision and made it available to users, they must upload documents using it and highlight each pertinent custom clause. For at least the first 30 contracts, and until the minimum accuracy threshold is met, a user must review and highlight contract data that matches the custom provision. You can simplify this user task using the Based-on Provision feature described above.
Theory
It is important to have a working understanding of the F score, as this is the final criterion by which you will measure the AI's performance in recognizing your custom provision. As the F score is a factor of accuracy, precision, and recall, it is worthwhile to have a basic understanding of these foundational concepts.
Accuracy
Accuracy describes the ratio of true positive and negative identifications for all samples. The ratio of true positives detected to actual positives is classified as recall. The ratio of true predicted positive results to all (true and false) predicted positives results is called precision. These are combined to form an F score.
Precision
Precision is a measure of the AI's predictive correctness. For example, if the AI is asked to find apples in a mixed basket of fruit, a perfect precision score of 1.00 means every fruit it found was an apple. This does not indicate whether it found all the apples. Expressed mathematically:
precision = true positives / (true positives + false positives)
Recall
Recall is a measure of completeness. For example, if the AI is to find apples in a mixed basket of fruit, a perfect recall score of 1.00 means it found all the apples in the basket. This does not indicate it found only apples: it may have found some oranges too. Expressed mathematically:
recall = true positives / (true positives + false negatives)
Categorizing legal concepts has more variation than picking fruit, especially when the provisions are reviewed by different legal professionals; therefore, recall and precision may differ among annotators (one person’s recall of 0.90 may be someone else's 0.80). Remember this when using built-in provisions and reviewing annotations.
F Score
The F score is the harmonic mean of precision and recall. It provides a more sensitive measure of accuracy than precision or recall alone. Expressed mathematically:
F = 2 * [(precision * recall) / (precision + recall)].
The F score gives equal weight to both precision and recall for measuring a system's overall accuracy. Unlike other accuracy metrics, the total number of observations is not important. The F-score value can provide high-level information about an AI model’s output quality, enabling sensitive tuning to optimize both precision and recall.
When setting up custom provisions, you are asked to enter a desired minimum accuracy threshold. This is an F score, and Conga recommends you set this value to 65, which we have found optimally weights AI precision vs. trainer time.